เราเล่าจากการทดลองจริงในแล็บ ไม่ใช่ทฤษฎี — และให้หลักฐานพูดแทน
จุดเจ็บ: เครื่องมือดี ๆ มีเยอะ แต่ตั้งค่าครั้งแรกยาก คนส่วนใหญ่ติดตรงเริ่มไม่ถูก
เดิมพัน: เสียเวลาเป็นวันกับการตั้งค่าผิด ๆ ทั้งที่ทำให้ถูกตั้งแต่แรกได้
สิ่งที่เราทำในแล็บ: เปรียบเทียบ 15+ monitoring tools เลือก 6 ตัว open-source — Prometheus+Grafana, Wazuh SIEM, CrowdSec, ntopng, Uptime Kuma ครอบคลุม Performance, Security, Network, Uptime ด้วยงบ $0 ใช้ RAM 12% จาก 128 GB
Behind the Scenes
Dedicated Server ต้อง Monitor อะไรบ้าง?
เปรียบเทียบ 15+ tools เลือก 6 ตัว — ครอบคลุม Performance, Security, Network, Uptime ด้วยงบ $0
อัปเดตล่าสุด: 2026-03-26
สรุปสั้นๆ — อ่านแค่นี้ก็เข้าใจ
- Dedicated Server รัน Proxmox VE มี 5 VMs — ไม่มี monitoring = ไม่รู้ว่าพังเมื่อไหร่
- ถาม AI เปรียบเทียบ 15+ tools → เลือก 6 ตัว open-source ครอบคลุม 5 ด้าน
- ทุก tool เข้าถึงผ่าน Cloudflare Tunnel — ไม่เปิด port public สักตัว
- ใช้ RAM ~12% จากทั้งหมด — คุ้มค่ามากสำหรับ visibility ที่ได้
Server ล่มตอนตี 3 — ลูกค้าเจอ error ตั้งแต่เที่ยงคืน แต่ไม่มีใครรู้จนกว่าจะตื่นมาเช็คตอน 8 โมงเช้า
นั่นคือปัญหาที่เจอกับ Dedicated Server ที่รัน Proxmox VE — AMD Ryzen 9 9950X3D, RAM 128 GB, ZFS 1.6 TB มี 5 VMs ทำงานอยู่ (GitLab, Docker containers หลายสิบตัว, Windows Server, Dev environment) แต่ไม่มี monitoring สักตัว
ความเสียหาย 8 ชั่วโมงที่ไม่รู้ว่า service หยุดทำงาน — วัดเป็นเงินไม่ได้ แต่วัดเป็นความเชื่อมั่นของลูกค้าได้ชัด
เลยถาม AI ว่า — ถ้าอยากดูแล server แบบ 360 องศา ครอบคลุมทั้ง Performance, Security, Network, Uptime ต้องใช้อะไรบ้าง? AI เปรียบเทียบมาให้ 15+ tools แล้วช่วยเลือกเหลือ 6 ตัว
ทำไม Server 5 ตัวต้องมี Monitoring?
Proxmox VE ที่รัน 5 VMs (3 Linux + 2 Windows) ต้องมี monitoring ครอบคลุม 5 ด้าน — Performance, Security, Uptime, Network, Alert — เพราะ VM แต่ละตัวรัน production services ที่ต่างกัน ถ้าตัวใดตัวหนึ่งล่มโดยไม่มีใครรู้ ความเสียหายจะสะสมทุกนาที
ลองนึกภาพ: VM ตัวหนึ่งรัน Docker containers มากกว่า 10 ตัว — GodsEye, Jigsaw API, n8n workflow, EmailHunter ถ้า VM นี้ล่มกลางดึก ทุก service หยุดพร้อมกัน
Server ที่ไม่มี monitoring เหมือนรถที่ไม่มี dashboard — ขับได้ แต่ไม่รู้ว่าน้ำมันจะหมดเมื่อไหร่

Zhangjiajie, China — สะพานแก้วกลางหมอก
เลือก Monitoring Stack ยังไง?
Monitoring stack สำหรับ Proxmox VE ที่เลือกมาประกอบด้วย 6 tools ใน 5 หมวด — Prometheus + Grafana (performance), Wazuh (security SIEM), CrowdSec (IPS), ntopng (network), Uptime Kuma (uptime) เลือกโดยให้ AI วิเคราะห์ข้อดีข้อเสียแล้วตัดสินใจจาก GUI ดี + resource ไม่หนัก + community ใหญ่
วิธีเลือก: ถาม AI ให้เปรียบเทียบ tools ทุกหมวดเป็นตาราง → ดูคะแนนทุกด้าน → ตัดสินใจเลือกตัวที่เหมาะสมที่สุด
Performance: Prometheus + Grafana ชนะเพราะอะไร?
| เกณฑ์ | Prometheus + Grafana | Zabbix 7.2 | Netdata |
|---|
| GUI สวย | 9/10 | 7/10 | 9/10 |
| Custom Dashboard | ยืดหยุ่นสูงสุด | จำกัด | จำกัด |
| RAM ที่ใช้ | 1-2 GB | 1.5-2 GB | 300 MB |
| เก็บข้อมูล | 90 วัน+ | ดี (DB) | 14 วัน |
ฟันธง: Prometheus + Grafana. Dashboard สวยที่สุด + เก็บข้อมูลได้ 90 วัน (Netdata ได้แค่ 14 วัน) Zabbix มี Proxmox template ดีมากแต่ GUI ไม่สวยเท่า
Security: Wazuh ครบจบในตัวเดียว
| เกณฑ์ | Wazuh | ELK Stack | OSSEC |
|---|
| ครอบคลุม | SIEM + HIDS + FIM + Vuln | Log platform | HIDS เท่านั้น |
| Agent | Linux + Windows | ต้อง Beats | Linux เป็นหลัก |
| Vulnerability | มีในตัว | ต้อง plugin | ไม่มี |
| RAM | 8 GB | 8-16 GB | 1 GB |
ฟันธง: Wazuh. ครบจบในตัวเดียว ไม่ต้องต่อ plugin เหมือน ELK ตัวเดียวได้ SIEM + Host Intrusion Detection + File Integrity + Vulnerability + Compliance มี MITRE ATT&CK mapping ด้วย (GitHub stars 11k+ ณ มี.ค. 2026)
Wazuh = 5 tools ในตัวเดียว — SIEM, HIDS, File Integrity, Vulnerability Scanner, Compliance Checker
IPS: CrowdSec — "Fail2ban ยุคใหม่"
CrowdSec ชนะ Fail2ban เพราะมี community threat intelligence — IP ที่ถูก ban ทั่วโลกจะถูกแชร์มาให้อัตโนมัติ ใช้ RAM แค่ 256 MB มี Cloudflare Bouncer ที่ ban IP ตั้งแต่ edge ก่อนถึง server (เหมาะกับ setup ที่ใช้ Cloudflare Tunnel อยู่แล้ว)
Network: ntopng — GUI สวยที่สุด + Real-time DPI
ntopng ได้ GUI 9/10 (สวยที่สุดในกลุ่ม network monitoring) พร้อม Deep Packet Inspection (DPI — ระบบวิเคราะห์ว่า traffic เป็น HTTP, DNS, SSH, YouTube, Netflix) ใช้ RAM 2 GB เทียบกับ Security Onion ที่กิน 16-32 GB
Uptime: Uptime Kuma — ติดตั้งง่ายสุด + Lark native
Uptime Kuma ติดตั้งง่ายที่สุด (10/10) ใช้ RAM แค่ 150 MB มี Status Page ในตัว + รองรับ Lark notification แบบ native (90+ notification providers) เทียบกับ Nagios/Icinga2 ที่ติดตั้งยากกว่ามากและไม่มี Status Page
6 tools, 5 หมวด, งบ $0 — open-source ทั้งหมด ครอบคลุม 360 องศา
สถาปัตยกรรม Monitoring ออกแบบยังไง?
สถาปัตยกรรมใช้ Private Network แยก monitoring traffic ออกจาก production — tools ทั้งหมดไม่เปิด public ต้องเข้าผ่าน Cloudflare Tunnel เท่านั้น ไม่ต้องเปิด port ให้ internet เห็น ออกแบบโดยถาม AI ว่าควรแยก network ยังไง แล้วทำตาม
☁️ Cloudflare Tunnel
เข้าถึง Grafana, Wazuh, ntopng, Uptime Kuma ผ่าน Tunnel — ไม่ต้องเปิด port
→
🔔 Lark Webhook
รับ alert จาก Alertmanager + Wazuh → แจ้งเตือนทีมทันที
▼
📊 node_exporter
ส่ง Host metrics — CPU, RAM, Disk, ZFS, Network
→
🌐 ntopng
Real-time traffic analysis + Deep Packet Inspection
→
🛡️ CrowdSec
Community threat intelligence + Cloudflare Bouncer — auto-ban
▼
📈 Prometheus
เก็บ metrics ทุก 15 วินาที + ประเมิน alert rules 8 ข้อ
→
📊 Grafana
"Single pane of glass" — dashboard ดูทุกอย่างในที่เดียว
→
✅ Uptime Kuma
ตรวจ 33 services + Status page ให้ทีมดูได้ทันที
▼
🔒 Wazuh Manager
SIEM + HIDS — รับ events จากทุก agent วิเคราะห์ security
→
🖥️ Wazuh Dashboard
Security dashboard + MITRE ATT&CK mapping + compliance
▼
🐧 Linux VMs ×3
node_exporter + Wazuh Agent + CrowdSec — ครบ 3 ชั้น
→
🪟 Windows VMs ×2
windows_exporter + Wazuh Agent — ครบ 2 ชั้น
ทำไมใช้ LXC แทน VM? — LXC container มี overhead แทบเป็นศูนย์ boot ได้ใน 1-3 วินาที กิน RAM overhead แค่ ~50 MB เทียบกับ VM ที่ต้อง 300-500 MB

🛤️
เส้นทางยาว แต่คุ้มค่า
Setup monitoring เหมือนสร้างถนน — ลงทุนครั้งเดียว ใช้ไปได้นาน
ใช้ Resource เท่าไหร่?
Monitoring stack ใช้ RAM ประมาณ 15.3 GB จาก 128 GB (~12%) และ disk ประมาณ 156 GB จาก ZFS 1.6 TB — เหลือ resource เพียงพอสำหรับ production ทุกตัว ถือว่าคุ้มค่ามากสำหรับ visibility ที่ได้ (วัดจากสัดส่วน RAM ที่ใช้ เทียบกับการมี monitoring ครบ 5 ด้าน)
~15 GB
RAM สำหรับ Monitoring
ส่วนใหญ่กิน RAM คือ Wazuh (8 GB สำหรับ SIEM + OpenSearch) กับ Grafana + Prometheus (6 GB) ที่เหลือเป็น tools เบาๆ — CrowdSec 256 MB, Uptime Kuma 150 MB, node_exporter 20 MB
ข้อมูล Monitoring ไหลยังไง?
Data flow เริ่มจาก exporters บนทุก VM ส่ง metrics ไป Prometheus ทุก 15 วินาที → Prometheus เก็บ + ประเมิน alert rules → Grafana ดึงข้อมูลแสดง dashboard → Alertmanager จัดกลุ่ม alerts แล้วส่ง Lark webhook ทันที
📥
Exporters
node / windows / pve
→
⚙️
Prometheus
scrape 15s / เก็บ 90 วัน
→
📊
Grafana
PromQL / Dashboard
→
🚨
Alertmanager
group / dedup / route
→

Dobrota, Montenegro — ภูเขาริม Adriatic Sea
Alert Rules ตั้งยังไงให้ไม่พลาด?
Prometheus alert rules 8 ข้อครอบคลุม 3 กลุ่ม — performance (CPU/RAM สูงผิดปกติ), storage (disk/ZFS เต็ม), availability (host/VM down) ทุก alert ส่งตรงถึง Lark Chat ภายในไม่กี่วินาทีหลังเกิดปัญหา
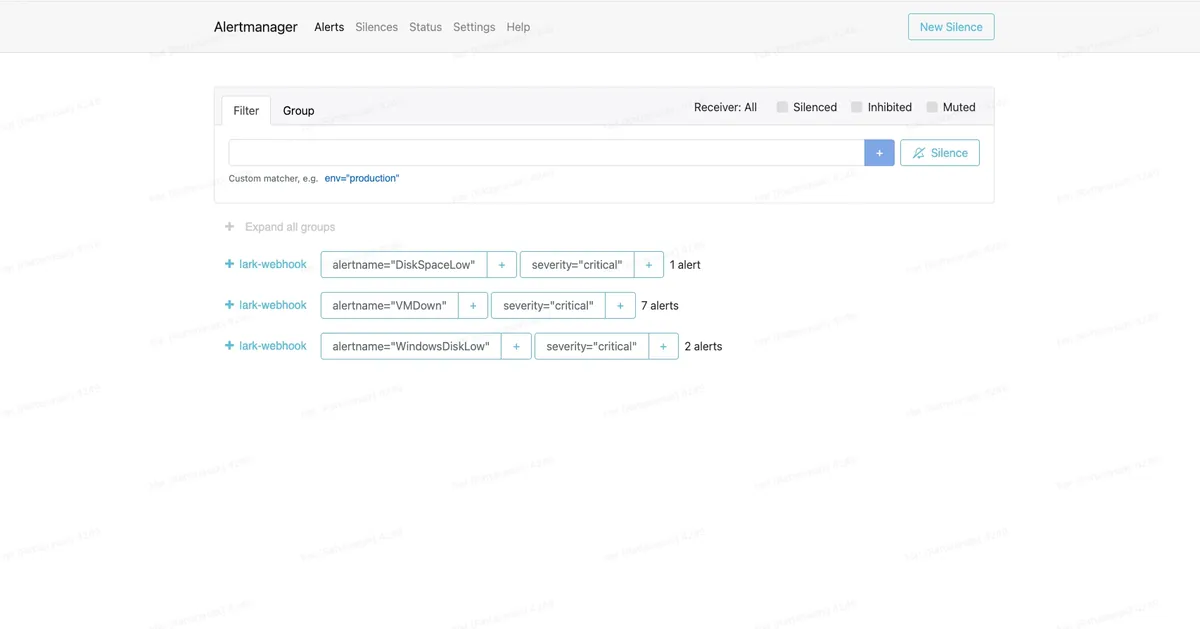
Alert Rules 8 ข้อ: HighCPU (>90% 5 นาที), HighMemory (>90% 5 นาที), DiskSpaceLow (>85%), HostDown (down 2 นาที), VMDown (status ≠ running), ZFSPoolHigh (>80%), WindowsHighCPU (>90%), WindowsDiskLow (>85%)
นอกจากนี้ Wazuh จะ alert เมื่อเจอ brute-force, file integrity change, rootkit, vulnerability (CVE) — และ CrowdSec จะ auto-ban IP ที่ทำ SSH brute-force หรืออยู่ใน community blocklist โดยอัตโนมัติ
3 ชั้นป้องกัน: Prometheus (performance) + Wazuh (security) + CrowdSec (auto-ban) — ครอบคลุมทุกมุม
เริ่ม Setup Monitoring Stack ยังไง?
Setup monitoring stack สำหรับ Proxmox VE ใช้เวลาประมาณ 2-3 ชั่วโมงถ้าสั่ง AI ทำทั้งหมดผ่าน Cursor — ทั้ง 7 ขั้นตอนไม่ได้พิมพ์ command เอง AI ทำให้ทุก step (เวลาวัดจากการทำจริงครั้งแรก รวมเวลาตรวจสอบแต่ละ step)
01สร้าง Private Network (⏱️ ~10 นาที)
สั่ง AI สร้าง network bridge แยก monitoring traffic ออกจาก production → เพิ่ม NIC ใหม่ให้ทุก VM
02สร้าง LXC: Monitoring Stack (⏱️ ~30 นาที)
สั่ง AI สร้าง LXC container 4 vCPU / 6 GB RAM → ติดตั้ง Prometheus + Grafana + Alertmanager + pve-exporter + Uptime Kuma
03สร้าง LXC: Wazuh SIEM (⏱️ ~30 นาที)
สั่ง AI สร้าง LXC container 4 vCPU / 8 GB RAM → ติดตั้ง Wazuh all-in-one (Manager + Indexer + Dashboard)
04ติดตั้ง Host-level Tools (⏱️ ~15 นาที)
สั่ง AI ติดตั้ง node_exporter + ntopng + CrowdSec + Firewall Bouncer บน Proxmox host โดยตรง
05Deploy Agents ทุก VM (⏱️ ~30 นาที)
สั่ง AI SSH เข้า VM แต่ละตัว: Linux → node_exporter + Wazuh Agent + CrowdSec | Windows → windows_exporter + Wazuh Agent
06ตั้ง Alert + Notification (⏱️ ~15 นาที)
สั่ง AI สร้าง alert rules 8 ข้อใน Prometheus + config Alertmanager ส่ง Lark → ทดสอบ fire alert จริง
07Cloudflare Tunnel + ทดสอบ (⏱️ ~20 นาที)
สั่ง AI ตั้ง Cloudflare Tunnel สำหรับทุก dashboard → ทดสอบเข้าถึงผ่าน browser → ตรวจว่าข้อมูลแสดงถูกต้อง
Prompt สำหรับสั่ง AI ช่วย Setup มีอะไรบ้าง?
2 prompts นี้ copy ไปใช้กับ Cursor AI ได้เลย — ปรับ variables ตาม spec เครื่องตัวเอง ทั้ง 2 ชุดเป็น production-ready ที่ใช้จริงตอน setup
Cursor Prompt: "ช่วยเปรียบเทียบ monitoring tools สำหรับ Proxmox server — spec คือ {{server_spec}} มี {{vm_count}} VMs ({{vm_details}}) ต้องการ Performance + Security + Network + Uptime monitoring งบ open-source เท่านั้น เปรียบเทียบเป็นตาราง: GUI (1-10), RAM ที่ใช้, ติดตั้งง่าย (1-10), จุดแข็ง, จุดอ่อน สรุปท้ายว่าแนะนำ stack ไหน + resource ที่ต้องใช้รวม + ข้อควรระวัง"
Variables: {{server_spec}} = spec เครื่องจริง เช่น AMD Ryzen 9, 128 GB RAM | {{vm_count}} = จำนวน VM | {{vm_details}} = รายละเอียด เช่น 3 Linux + 2 Windows
ทำไมได้ผล: กำหนด context (Proxmox spec) + output format (ตาราง) + constraints (open-source) + actionable summary — AI ไม่ต้องเดา
Cursor Prompt: "ช่วย setup monitoring stack บน Proxmox LXC container — สร้าง LXC (Debian 12, {{cpu}} vCPU, {{ram}} RAM, {{disk}} disk) ติดตั้ง Prometheus (retention 90 วัน, scrape 15s) + Grafana (import dashboard IDs: 1860, 10347) + Alertmanager (route ไป {{notification_url}}) + alert rules: CPU>90% 5m, RAM>90% 5m, Disk>85% 5m, HostDown 2m — ทำทีละ step แสดงผลลัพธ์ที่คาดหวังให้ตรวจ"
Variables: {{cpu}} = จำนวน vCPU | {{ram}} = RAM เช่น 6G | {{disk}} = Disk เช่น 50G | {{notification_url}} = Lark/Slack webhook URL
Token Tip: ถ้าใช้ Cursor สั่งผ่าน SSH session ของ Proxmox ได้เลย — AI จะรัน command จริงให้ ลดการ copy-paste

🏔️
เห็นภาพรวมชัดเจน
Monitoring ที่ดี = เห็นทุกอย่างสะท้อนชัดเหมือนทะเลสาบกระจก
จะดูอะไร ไปที่ไหน?
ตารางสรุปสำหรับทีม — อยากดูอะไร เปิด tool ไหน เมนูอะไร ดูได้ทันทีไม่ต้องจำ ทั้ง 8 กรณีหลักที่ต้องเจอในการดูแล server ประจำวัน
| ต้องการดู | เปิด Tool | เมนู / Dashboard |
|---|
| ภาพรวมทุก VM | Grafana | Infrastructure → Server Overview |
| VM แต่ละตัวละเอียด | Grafana | Infrastructure → Proxmox via Prometheus → เลือก VM |
| Windows VM | Grafana | Infrastructure → Windows Exporter |
| ZFS / Storage | Grafana | Infrastructure → ZFS |
| Docker แต่ละ container | Grafana | Folder ของ Project (GodsEye / Jigsaw / ...) |
| Security events | Wazuh | Security Events / Vulnerability / Agents |
| Service up/down | Uptime Kuma | Dashboard — เขียว = UP, แดง = DOWN |
| Network traffic | ntopng | Hosts / Flows / Protocols |
Grafana Dashboard — อ่านค่า Server, VM, Docker ยังไง?
Grafana มี 4 ระดับ dashboard — ภาพรวม Server, แต่ละ VM, Windows VM, ZFS Storage + 7 project folders สำหรับ Docker containers ทุก dashboard เข้าผ่าน Grafana เลือก folder ทางเมนูซ้าย แต่ละ dashboard มีค่าปกติกับค่าอันตรายที่ต้องระวัง
Server Overview — ดูภาพรวมทุก VM
เข้า Grafana → Dashboards → Infrastructure → Server Overview
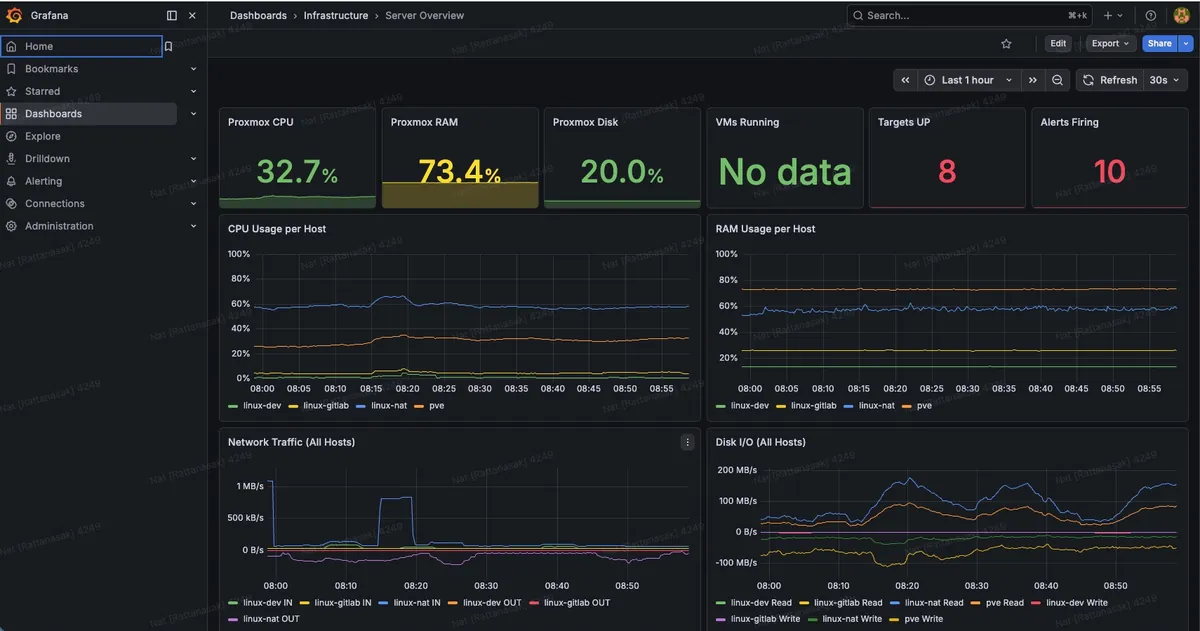
| ค่าที่เห็น | อ่านยังไง | ค่าอันตราย |
|---|
| Proxmox CPU % | CPU ของ Host ทั้งเครื่อง | > 85% ต้องดูว่า VM ไหนกิน |
| Proxmox RAM % | RAM ทั้งเครื่อง | > 90% = อันตราย |
| CPU per Host (กราฟ) | เส้นแต่ละสี = แต่ละ VM — เส้นสูงสุด = VM นั้นกิน CPU มากสุด | เส้นค้างสูง > 90% นาน 5+ นาที |
| RAM per Host (กราฟ) | เหมือนกัน — เส้นสูง = VM กิน RAM เยอะ | เส้นค้างเกือบชน limit |
Tips: กราฟมี spike ผิดปกติ? Hover ดู timestamp แล้วไปตรวจ log ช่วงนั้น / CPU สูงต่อเนื่อง? ดู per core ว่า core ไหนสูง อาจมี process ค้าง / RAM เต็ม? ดู swap ด้วย ถ้า swap สูง = ต้องเพิ่ม RAM
Per-VM Detail — แต่ละ VM ละเอียดทุกมิติ
เข้า Infrastructure → Proxmox via Prometheus → เลือก VM จาก dropdown
| ค่า | หมายความว่า | ปกติ | อันตราย |
|---|
| CPU Usage | % ที่ VM ใช้ CPU | < 70% | > 90% นาน 5+ นาที |
| RAM Used | RAM ที่ใช้จริง | < 80% | > 90% |
| Disk Usage | พื้นที่ disk | < 70% | > 85% |
| Network In/Out | Traffic (bytes/sec) | ขึ้นกับ service | spike ผิดปกติ |
| Disk I/O | อ่าน/เขียน disk | ขึ้นกับ workload | สูงต่อเนื่อง = bottleneck |
Windows VM — ดู VM 101, 105 โดยเฉพาะ
เข้า Infrastructure → Windows Exporter Dashboard
| ค่า | อ่านยังไง |
|---|
| CPU per Core | เห็นแต่ละ core — core ไหนสูง = process ผูกกับ core นั้น |
| Logical Disk Free | แยกต่อ drive (C:, D:) — ถ้า < 15% ต้องจัดการ |
| Memory Usage | Committed Bytes vs Physical Memory |
| Service Status | Windows Services ที่รัน — service สำคัญหยุดเห็นทันที |
ZFS Storage — สิ่งที่ต้องดูเป็นพิเศษ
เข้า Infrastructure → ZFS
| ค่า | อ่านยังไง | อันตราย |
|---|
| Pool Usage % | พื้นที่ ZFS ที่ใช้ไป | > 80% = performance ลดหนัก |
| Fragmentation % | ความกระจัดกระจายของข้อมูล | > 70% = ต้อง plan |
| ARC Hit Rate | Cache hit (ZFS ใช้ RAM เป็น cache) — ยิ่งสูงยิ่งดี | < 80% = RAM ไม่พอสำหรับ cache |
ZFS Pool เกิน 80% = performance ลดหนัก / Fragmentation เกิน 70% = ต้อง plan ทันที — 2 ค่านี้ดูทุกเดือน
Docker Container Monitoring — ดู Resource แต่ละ Project ยังไง?
cAdvisor (Container Advisor จาก Google) เก็บ metrics ของทุก Docker container แล้วส่งให้ Prometheus ทุก 15 วินาที — Grafana แยก dashboard ตาม project ดูได้ว่าแต่ละ container กิน CPU กี่ % RAM กี่ MB ไม่ต้อง SSH เข้าไปรัน docker stats
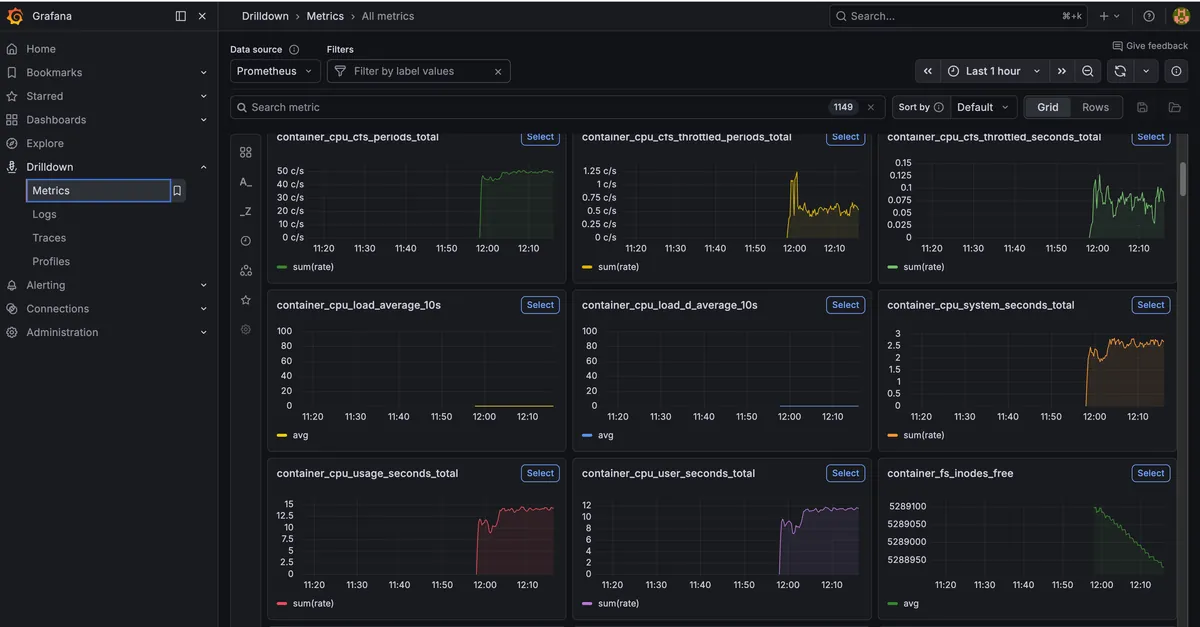
Dashboard แยกตาม Project
| Grafana Folder | Containers ที่เห็น |
|---|
| GodsEye | godseye-web, godseye-engine, godseye-timescaledb |
| Jigsaw | jigsaw-api, jigsaw-admin, jigsaw-rag, jigsaw-worker, postgres, redis |
| EmailHunter | emailhunter-api, n8n, searxng, dashboard |
| ScanlyIQ | scanlyiq-app, db, redis |
| EA-by-AI | ea-ai-dashboard, grafana, n8n, postgres |
| n8n-Workflow | n8n main |
| Infrastructure-Services | portainer, logto, infisical, duplicati, watchtower |
แต่ละ Project Dashboard แสดง: Total CPU % (รวมทุก container), Total RAM (รวมทั้ง project), Containers Running (จำนวนที่ทำงาน) + กราฟ CPU/RAM/Network per Container
เปิด Grafana → เลือก folder ของ project → เห็นทุก container ในที่เดียว ไม่ต้อง SSH เข้าไป
Wazuh + Uptime Kuma + ntopng — อ่านค่ายังไง?
3 tools สำหรับ Security, Uptime, Network — ใช้ร่วมกันจะเห็นภาพครบ ถ้า service DOWN (Uptime Kuma) → ดูว่ามี security event ไหม (Wazuh) → ดูว่า traffic ผิดปกติไหม (ntopng)
Wazuh — Security Events
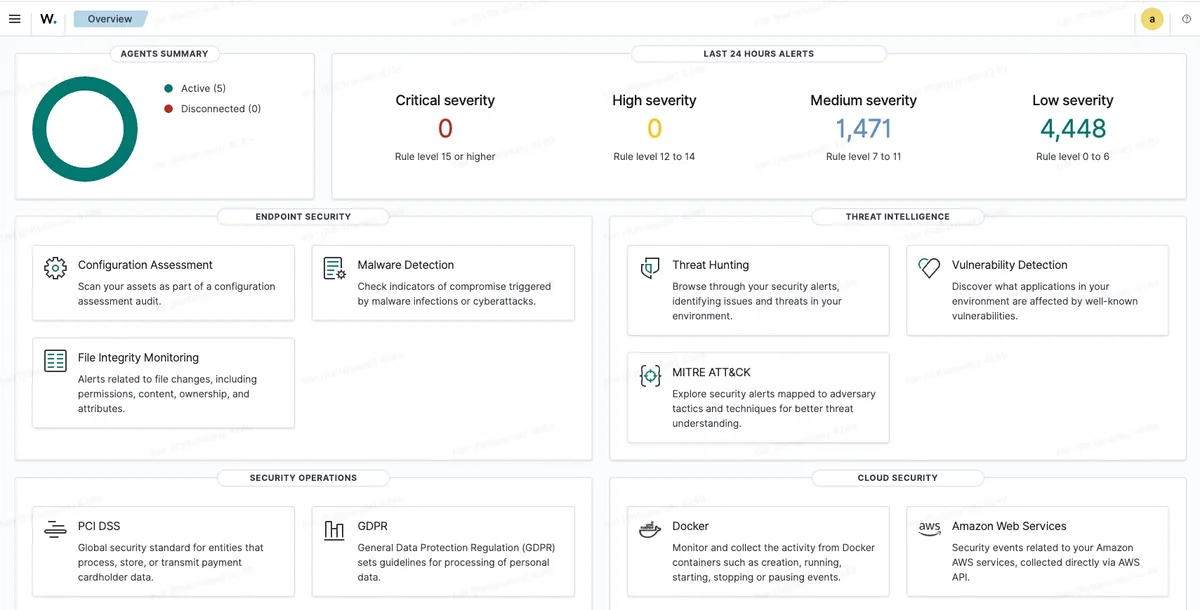
| เมนู | ดูอะไร | ต้องระวัง |
|---|
| Security Events | ทุก event จากทุก VM — filter ตาม agent/level | Level 10+ = ตรวจ / Level 12+ = ดูทันที |
| Vulnerability | CVE ที่พบในระบบ — เรียงตาม severity | Critical + High = ต้อง patch |
| Agents | สถานะ agent ทุกตัว | ต้อง Active ทั้ง 5 ตัว |
Tips: Top 5 alerts บน dashboard → ดูว่า alert ไหนเกิดซ้ำบ่อย อาจมี pattern ที่ต้องแก้ที่ต้นเหตุ
Uptime Kuma — Service Status
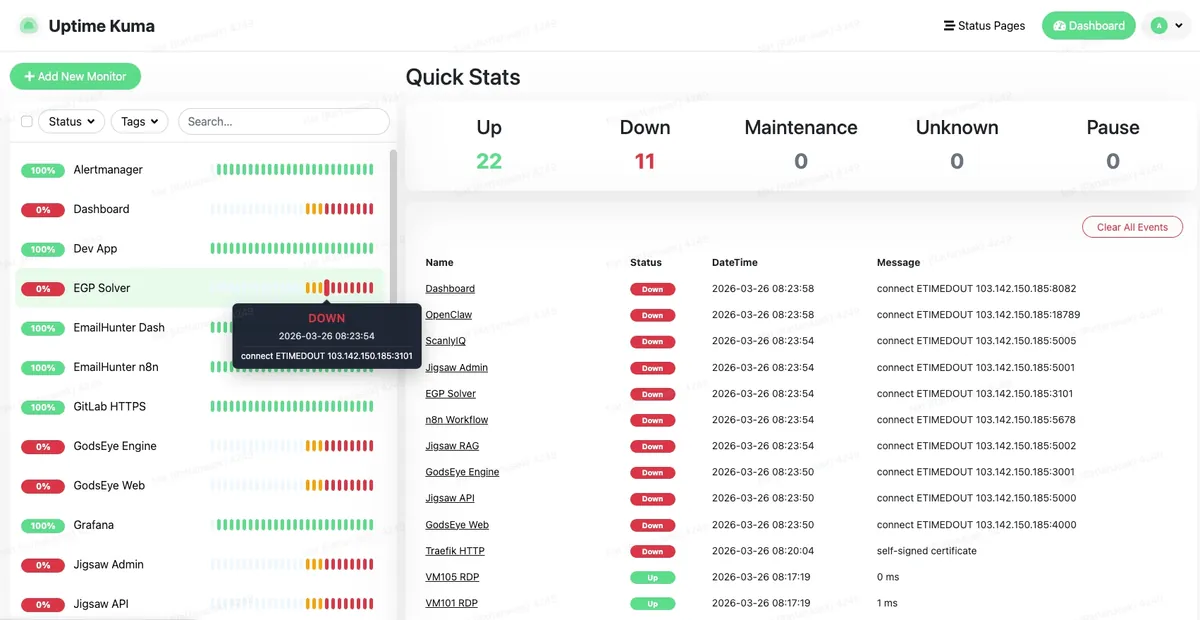
| สี | หมายความว่า | ทำอะไรต่อ |
|---|
| เขียว | UP — service ทำงานปกติ | ไม่ต้องทำอะไร |
| แดง | DOWN — service ล่ม | ดู response time ก่อนหน้า: ช้าขึ้นเรื่อยๆ = resource ไม่พอ → ดู Grafana / down ทันที = crash → ดู Wazuh |
| เหลือง | Pending — กำลังตรวจ | รอสักครู่แล้วดูอีกที |
ntopng — Network Traffic
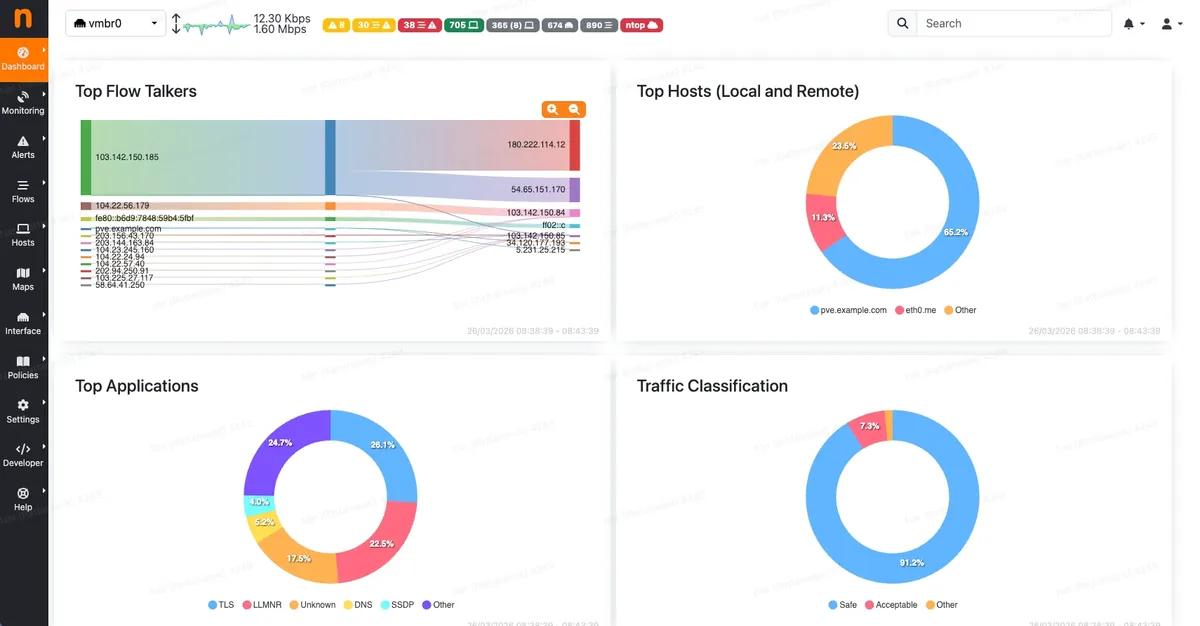
| เมนู | ดูอะไร |
|---|
| Hosts | Top talkers — VM/IP ไหนใช้ bandwidth เยอะสุด |
| Flows | ทุก connection (source → destination, port, protocol) |
| Protocols | แยกตาม app — HTTP, SSH, DNS, MySQL... |
Tips: Traffic จาก IP ที่ไม่รู้จัก? → ตรวจใน Wazuh ว่ามี alert ไหม / Bandwidth สูงผิดปกติ? → ดู Flows ว่า connection ไหนกิน
ดูแลรักษา Monitoring Stack ยังไง?
Monitoring stack ต้องดูแล 3 ระดับ — Daily (2 นาที ดู Uptime Kuma + Lark), Weekly (15 นาที ดู Grafana trend + Wazuh events), Monthly (30 นาที ตรวจ ZFS + disk + update agents) ถ้าไม่ดูแล monitoring ที่สร้างมาก็กลายเป็นของตกแต่ง (เวลาวัดจากการทำจริงเฉลี่ย 4 สัปดาห์)
Daily (2 นาที): เปิด Uptime Kuma ดูว่า 33 services ยัง UP + เช็ค Lark ว่ามี alert ไหม
Weekly (15 นาที): Grafana ดู trend CPU/RAM/Disk ว่ามีตัวไหนขึ้นเรื่อยๆ + Wazuh ดู Security Events + CrowdSec ดูว่ามี IP ถูก ban กี่ตัว
ข้อควรระวัง: ZFS ห้ามเกิน 80% capacity (performance ลดอย่างมาก) + Prometheus retention 90 วัน = disk เพิ่มเรื่อยๆ ต้องเฝ้าดู + Wazuh logs ตั้ง retention 30-90 วันป้องกัน disk เต็ม
คำถามที่พบบ่อยมีอะไร?
ใช้ RAM 15 GB สำหรับ monitoring คุ้มไหม?
คุ้ม — จาก 128 GB ใช้ไปแค่ 12% แลกกับ visibility ครบ 360 องศา ถ้า production service หยุดทำงาน 8 ชั่วโมงโดยไม่มีใครรู้ ค่าเสียโอกาสมากกว่า RAM 15 GB หลายเท่า
คนไม่เขียน code ตั้ง monitoring stack ได้ไหม?
ได้ ถ้าใช้ AI ช่วยผ่าน Cursor — monitoring stack นี้ทั้งหมดสั่ง AI ทำ ไม่ได้พิมพ์ command เอง แต่ต้องเข้าใจ concept ว่าแต่ละ tool ทำอะไร เพื่อตัดสินใจ config ได้ Prompt ด้านบน copy ไปใช้ได้เลย
ทำไมไม่ใช้ Datadog หรือ New Relic?
Datadog ราคาประมาณ $15-23/host/เดือน × 7 hosts = ~4,000-5,700 บาท/เดือน (ราคา ณ มี.ค. 2026 จาก Datadog pricing page) open-source stack ไม่มีค่าใช้จ่าย + ข้อมูลอยู่ในเครื่องตัวเองปลอดภัยกว่า
ถ้า LXC monitoring เอง crash จะรู้ได้ยังไง?
ตั้ง external monitoring (เช่น UptimeRobot free tier) ดู Grafana URL จากข้างนอก ถ้า Grafana ตอบไม่ได้ = LXC มีปัญหา แจ้งเตือนผ่าน email/SMS — ใช้ monitoring ภายนอกจับ monitoring ภายในอีกชั้น
Wazuh กิน RAM 8 GB ลดได้ไหม?
ลดได้แต่ไม่แนะนำต่ำกว่า 6 GB — Wazuh Indexer (OpenSearch) เป็นตัวกิน RAM หลัก ถ้า agents น้อย (5 ตัว) อาจลดลงได้ แต่เมื่อ logs สะสมเยอะขึ้น RAM จะกินเพิ่ม ลด retention เหลือ 30 วันช่วยได้
สนใจสร้าง Monitoring Stack?
เริ่มจาก Prompt แรกด้านบน — ถาม AI ให้เปรียบเทียบ tools ที่เหมาะกับ spec เครื่อง ไม่ต้องทำทีเดียวทั้งหมด เริ่มจาก Prometheus + Grafana + Uptime Kuma ก่อน แล้วค่อยเพิ่ม Wazuh + CrowdSec + ntopng ทีหลัง
Server ที่มี monitoring ดีไม่ใช่ server ที่ไม่เคยมีปัญหา — แต่เป็น server ที่รู้ปัญหาก่อนจะกลายเป็นวิกฤต
Stack: Prometheus 3.3.0 + Grafana 12.4.2 + Wazuh 4.12.0 + CrowdSec + ntopng + Uptime Kuma 2.2.1 (ณ มี.ค. 2026)
#Proxmox #Monitoring #Grafana #Prometheus #Wazuh #CrowdSec #ntopng #UptimeKuma #DevOps #ServerMonitoring #OpenSource #Infrastructure
สิ่งที่ได้ และหลักคิด
ของจริงที่เอาไปใช้ต่อได้ ไม่ใช่แค่ไอเดีย หลักคิดของเราคือทำให้เป็นระบบที่ทำซ้ำได้และไม่พึ่งความจำคน
อยากเห็นระบบแบบนี้ทำงานกับงานของคุณ — ดู ViberQC และลงชื่อรอรอบทดลองที่ hilogiclabs.com


